How to Organize Multiple Device Sessions During an Incident
How to Organize Multiple Device Sessions During an Incident
Short answer
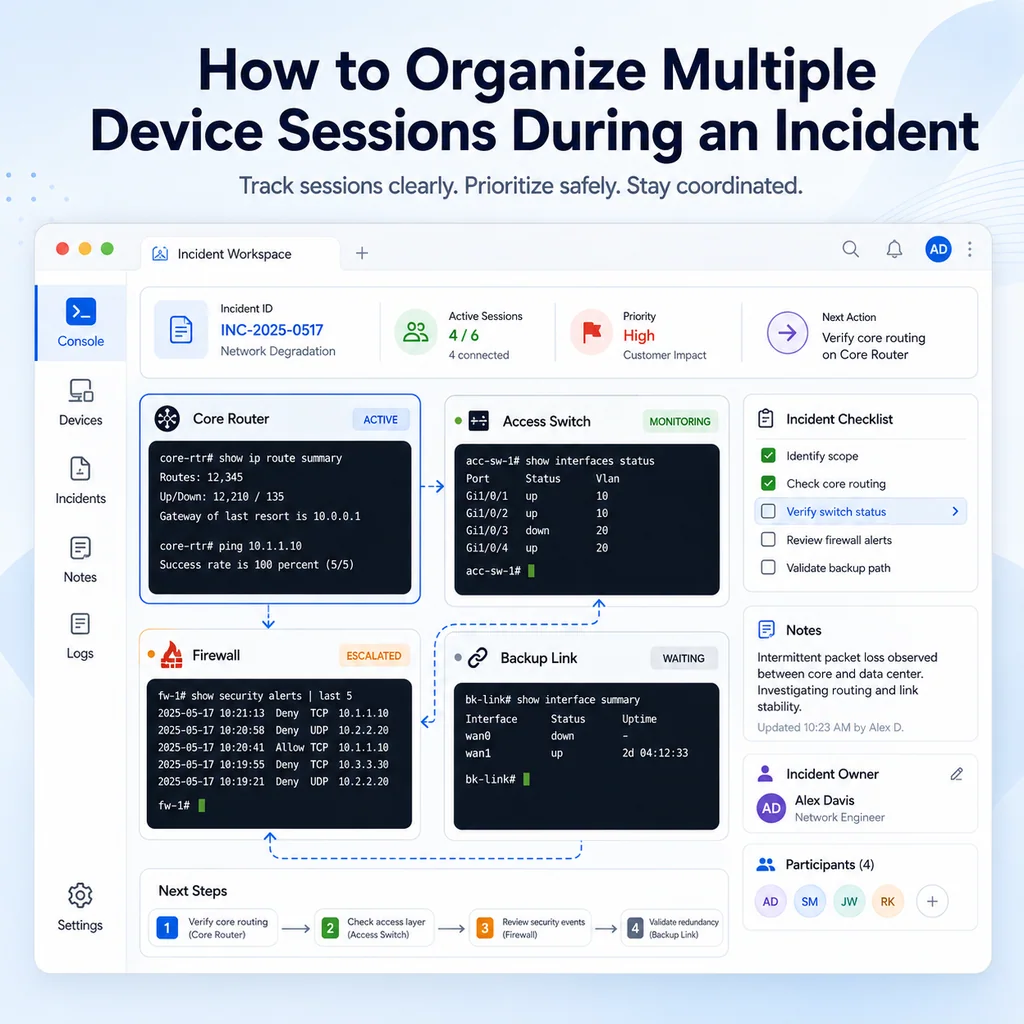
During an incident, multiple terminal sessions can become dangerous quickly. Organize them before the situation gets noisy. Name each session clearly, separate observation from change work, assign owners, keep a live session map, and document what each device is being used for.
A safe multi-device incident workflow looks like this:
- Identify every device involved.
- Decide which sessions are read-only and which are allowed to make changes.
- Give every session a clear name.
- Assign one owner per active device session.
- Keep a visible session map.
- Record the current mode, user, and access path for each session.
- Run commands one device at a time when possible.
- Document every change immediately.
- Close or archive sessions when they are no longer needed.
- Hand off context before another engineer continues.
The goal is simple: every open terminal should have a purpose, an owner, and a known target.
Why multiple sessions become risky during incidents
Incidents create pressure. People open sessions quickly because they need answers quickly. One engineer checks a router. Another checks a firewall. Someone opens a serial console. Someone else logs into a jump host. A third person watches logs on a server.
That is normal.
The risk starts when nobody knows which terminal is which.
Common problems include:
- Typing into the wrong session
- Running the right command on the wrong device
- Repeating the same check on multiple devices
- Making changes without telling the team
- Losing track of which sessions are read-only
- Leaving old root or admin sessions open
- Confusing production and staging
- Forgetting which SSH path or console path is being used
- Closing the only working recovery session
- Handoff notes that say “I’m in” but do not say where
During an incident, context is as important as access. A terminal without context is a risk.
Start with a session map
Before opening too many terminals, create a simple session map. It does not need to be complicated.
Use a format like this:
DEVICE / SESSION MAP
core-sw-01:
Owner: Alex
Access: SSH through jump-01
Purpose: check trunk state
Mode: read-only
Changes allowed: no
core-sw-02:
Owner: Priya
Access: serial console through rack controller port 4
Purpose: recover management access
Mode: changes allowed after approval
Changes allowed: yes, with incident lead approval
fw-01:
Owner: Morgan
Access: SSH
Purpose: check firewall logs and route table
Mode: read-only
Changes allowed: no
jump-01:
Owner: Sam
Access: SSH
Purpose: access path only
Mode: no changes
Changes allowed: no
This map answers the most important questions:
- Which devices are open?
- Who owns each session?
- Why is each session open?
- Is the session allowed to change anything?
- What access path is being used?
Keep this map visible in the incident notes, ticket, runbook, or shared workspace.
Name every session clearly
Bad session names create confusion.
Avoid names like:
server
switch
ssh
console
prod
router
Use names that describe the actual target and access method:
prod-core-sw-01-ssh
prod-core-sw-02-console
fw-01-readonly
jump-01-access-only
app-03-logs
A good session name should tell you:
- Environment
- Device or host
- Access type
- Purpose if useful
Examples:
prod-fw-01-ssh-routes
prod-core-sw-02-console-recovery
staging-app-03-logs
jump-01-access-path
If you change what a session is used for, rename it or document the change. Do not let old labels lie.
Separate observation sessions from change sessions
Not every terminal should be allowed to make changes.
During an incident, divide sessions into two categories:
OBSERVE:
Used for show commands, logs, status checks, monitoring, and verification.
CHANGE:
Used for configuration changes, restarts, reloads, rollback, recovery, or repair.
Example session map:
core-sw-01: OBSERVE only
core-sw-02: CHANGE allowed after approval
fw-01: OBSERVE only
app-03: OBSERVE only
This reduces accidental changes. It also helps the incident lead understand where risk exists.
For network devices, the difference can be visible in the prompt:
switch>
switch#
switch(config)#
switch(config-if)#
A session in configuration mode should be treated as a change session.
Assign one owner per device session
Each active session should have one clear owner.
The owner is responsible for:
- Knowing what device the session is connected to
- Keeping the session label accurate
- Running commands only when appropriate
- Reporting important output
- Documenting changes
- Closing the session when finished
This does not mean only one person can look at the session. It means only one person is accountable for what happens in it.
A simple ownership note:
Session owner:
core-sw-01 SSH: Alex
core-sw-02 console: Priya
fw-01 SSH: Morgan
app-03 logs: Sam
If ownership changes, update the note:
14:35 - core-sw-02 console ownership moved from Priya to Alex.
Current mode: privileged EXEC.
No config mode active.
Last command: show interfaces trunk.
For a deeper handoff workflow, see Command Handoffs: How to Pass Terminal Work to Another Engineer Safely.
Confirm identity in every session
Every session should start with identity checks.
For Linux or Unix-like systems:
hostname
hostname -f
whoami
pwd
date
ip addr show
ip route
For network devices:
show version
show running-config | include hostname
show inventory
show clock
show users
show ip interface brief
For serial console sessions, also document the physical or controller path:
Console path: rack controller port 4 -> core-sw-02
Prompt: core-sw-02#
Rack label: core-sw-02
Access type: serial console
Do not trust only the tab title. Do not trust only the prompt. Use multiple identity checks.
For a full wrong-device prevention workflow, see How to Avoid Working on the Wrong Server or Network Device.
Keep jump hosts separate
Jump hosts are especially easy to confuse with target systems.
A jump host session should be labeled as a jump host, not as the final device.
Example:
jump-01-access-only
If you connect from the jump host to a target, document the full path:
laptop -> jump-01 -> app-03
A safe session note:
Session: app-03-ssh
Path: laptop -> jump-01 -> app-03
User: deploy
Current directory: /opt/app/current
Purpose: check application logs
Change mode: no changes approved
If you are still on the jump host, do not run target commands there by mistake.
Check after every connection step:
hostname
whoami
pwd
Keep serial console sessions protected
During an incident, a serial console session may be your best recovery path. Do not close it casually.
A serial console session should have a clear note:
Device: core-sw-02
Access: serial console
Path: rack controller port 4
Owner: Priya
Purpose: recovery path if SSH fails
Current mode: privileged EXEC
Changes allowed: only with incident lead approval
Do not close: yes
This is especially important when the network is unstable. If SSH drops, the console session may be the only reliable path left.
If the console session shows bootloader, ROMMON, recovery shell, or an unexpected prompt, document that state before doing anything else.
For first-time rack access workflows, see Serial Console Runbook for First-Time Rack Access.
Reduce the number of open terminals
More terminals do not always mean faster recovery.
Too many sessions can create noise, duplicate work, and wrong-device risk.
During an incident, ask:
- Is this session still needed?
- Does it have an owner?
- Does it have a clear purpose?
- Is it read-only or change-capable?
- Can it be closed safely?
- Is this an old session from before the incident?
A cleanup note might look like this:
Closed:
app-02 SSH - no longer needed
old jump-01 session - replaced by labeled jump-01-access-only
Kept open:
core-sw-02 console - recovery path
fw-01 SSH - active route checks
app-03 logs - active application verification
Closing unused sessions reduces the chance of typing into the wrong terminal.
Use a command queue for changes
When multiple people are working, do not let everyone make changes at the same time unless the incident process requires it.
Create a command queue for risky actions:
COMMAND QUEUE
1. core-sw-02
Owner: Priya
Command: add VLAN 40 back to trunk Gi1/0/24
Condition: only after trunk state is confirmed
Approval: pending
2. fw-01
Owner: Morgan
Command: remove temporary deny rule
Condition: only if logs confirm it is blocking management traffic
Approval: pending
3. app-03
Owner: Sam
Command: reload nginx
Condition: only after config test passes
Approval: approved
This makes sequencing visible.
It also prevents two engineers from making conflicting changes at the same time.
Run one risky command at a time
If several devices are involved, avoid making changes everywhere at once.
A better flow:
- Verify the target.
- Announce the command.
- Run the command.
- Capture output.
- Verify the result.
- Update the session map.
- Move to the next action.
Example:
About to run on core-sw-02:
show interfaces trunk
Mode: read-only
Purpose: confirm VLAN 40 trunk state
For a change command:
About to run on core-sw-02:
switchport trunk allowed vlan add 40
Mode: config mode
Purpose: restore management VLAN on trunk
Approval: incident lead approved at 14:42
Rollback: remove VLAN 40 from trunk if unexpected impact occurs
This short pause helps everyone stay aligned.
Avoid copy-paste mistakes
Copy and paste is risky during incidents because the wrong terminal may be active.
Before pasting:
- Confirm the active session name.
- Confirm the prompt.
- Confirm the device.
- Confirm the command applies to this device.
- Paste one command at a time when possible.
- Avoid pasting multi-line configuration into an unstable console.
- Watch the echoed command before pressing Enter if the terminal does not auto-submit.
High-risk commands include:
reload
reboot
shutdown
delete
erase
configure terminal
write memory
copy running-config startup-config
systemctl restart
rm
dd
mkfs
A safe habit:
Read command in notes -> confirm target -> paste one command -> verify prompt/output -> document result
For deeper guidance, see Safe Copy-Paste Habits for SSH and Serial Console Work.
Track what has changed
During an incident, every change should be documented immediately.
Use a simple change log:
CHANGE LOG
14:21 - fw-01 - Morgan
Action: reviewed firewall logs
Change: none
Result: deny rule found for management subnet
14:28 - core-sw-02 - Priya
Action: added VLAN 40 to trunk Gi1/0/24
Change: running config changed, not saved
Result: management ping restored from jump host
14:34 - app-03 - Sam
Action: reloaded nginx
Change: service reload only
Result: HTTPS check OK
Notice that the log includes both changes and important non-change findings. That helps later when reviewing the incident.
Mark unsaved network changes clearly
On network devices, running configuration and saved configuration may be different.
During an incident, this matters a lot.
If a change is active but not saved, write it clearly:
core-sw-02:
Running config changed.
Startup config not updated.
Do not reload until save decision is made.
If a save is approved and completed, document that too:
14:50 - core-sw-02
Action: saved running config to startup config
Approval: incident lead
Verification: management access restored and trunk state confirmed
Do not let “it is working now” automatically become “save it.” Saving should be a deliberate decision.
Keep verification sessions separate
It is useful to have one session for making a change and another for verifying the result.
Examples:
core-sw-02-console-change
jump-01-verify-management
monitoring-dashboard-readonly
app-03-logs-readonly
This helps answer two different questions:
- Did the command succeed locally?
- Did the service or network recover from the user side?
For example, after changing a switch trunk, verify from the management side:
ping management IP from jump host
SSH to management IP
Check monitoring recovery
Confirm expected interface state
Do not rely only on the device saying the command was accepted.
Use time stamps
Time stamps matter during incidents.
They help correlate:
- Commands
- Logs
- Monitoring alerts
- User reports
- Interface flaps
- Reboots
- Recovery events
Add time stamps to session notes:
14:12 - opened console to core-sw-02
14:14 - confirmed hostname and version
14:18 - found VLAN 40 missing from trunk
14:28 - added VLAN 40 back to trunk
14:30 - management ping restored
14:35 - SSH restored from jump host
If device time appears wrong, note that too:
Device clock appears 18 minutes behind local time.
Use local incident timestamps in notes.
Plan handoffs before people leave
Incidents often last longer than expected. Someone may need to step away.
Before a session owner leaves, capture:
- Device name
- Access path
- Current mode
- Commands already run
- Changes made
- Unsaved changes
- Still-running commands
- Next recommended step
- Do-not-do warnings
- Rollback notes
A handoff note:
HANDOFF - core-sw-02 console
Owner leaving: Priya
New owner: Alex
Access: serial console through rack controller port 4
Current mode: privileged EXEC, not config mode
Changes made: VLAN 40 added to trunk Gi1/0/24
Saved: no
Verification: management ping restored, SSH restored
Do not do: do not reload until save decision is made
Next step: incident lead to decide whether to save config
Rollback: remove VLAN 40 from trunk if unexpected impact appears
This prevents the next engineer from inheriting an unknown terminal state.
Multi-device incident checklist
Use this checklist when several device sessions are open.
[ ] Every session has a clear name.
[ ] Every session has one owner.
[ ] Every session has a purpose.
[ ] Every session is marked observe or change.
[ ] Target identity was confirmed in each session.
[ ] Jump host sessions are clearly labeled.
[ ] Serial console sessions are protected and not closed casually.
[ ] Unused sessions are closed.
[ ] Risky commands are queued and approved.
[ ] Changes are run one at a time where possible.
[ ] Copy-paste is controlled.
[ ] Unsaved network changes are documented.
[ ] Verification is done from outside the changed device.
[ ] Time stamps are recorded.
[ ] Handoffs are written before owners leave.
Common mistakes to avoid
Keeping too many unlabeled sessions open
If every tab says “ssh” or “console,” you are relying on memory. That is not enough during an incident.
Letting everyone make changes at once
Parallel diagnosis can be useful. Parallel uncoordinated changes are dangerous.
Closing the only console session
During a network incident, the console may be your recovery path. Confirm before closing it.
Saving configuration too early
A temporary fix may restore access but still need review. Save only after the team decides it is the correct long-term state.
Not recording “no change” checks
If someone checked a device and made no change, document that. It prevents duplicate work.
Trusting one verification path
A device can look healthy locally while still failing from the user side. Verify from the affected path.
Where CliDeck fits
CliDeck is a browser-based workspace for SSH, serial console, runbooks, shared terminal workflows, controller management, and remote operations.
During incidents, the key need is organization. Operators need terminal access, but they also need context: session names, notes, device identity, access paths, handoff details, and runbook steps.
CliDeck does not replace incident command or careful engineering judgment. But a clear browser-based workspace can help teams keep related sessions and notes closer together while working through the problem.
For related workflows, see What to Check Before Restarting a Network Service Over SSH and Terminal Notes That Actually Help During Troubleshooting.
Final thought
During an incident, the hardest part is not always getting access. Sometimes the hardest part is keeping access organized.
Every open session should answer three questions: what device is this, who owns it, and what is it for?
If the team can answer those questions, multiple terminal sessions become a controlled workflow instead of a source of new mistakes.